In the realm of education and examinations, creating mock questions for legal tests has traditionally been a humanities-driven process, relying heavily on expert intuition and manual design. However, with the advent of large language models (LLMs), we can revolutionize this approach by infusing it with STEM thinking — converting textual logic into quantifiable, data-driven insights. This blog delves into how LLMs can bridge this gap, offering a scalable framework for generating educational content.
Our journey began with a goal to develop a set of legal exam mock questions that reflect real-world patterns — covering key topics, balancing difficulty levels, and aligning with current legal trends. Initially, the process seemed rooted in subjective expertise, but we recognized an opportunity to apply a more scientific methodology. The question was: how can we quantify the inherently narrative nature of legal problems to ensure consistency and quality?
Legal question design traditionally hinges on the nuanced understanding of legal experts, lacking standardized metrics. This prompted a shift toward a STEM-inspired approach. By analyzing patterns within legal content — such as the frequency of topic combinations or the complexity of reasoning — we can extract measurable indicators. For instance, identifying which legal concepts frequently appear together or assessing the cognitive demand of a question allows us to define clear, data-based parameters.
Enter LLMs, which serve as a powerful tool to operationalize this transformation. By feeding these models with structured prompts based on quantified insights (e.g., topic co-occurrence or difficulty thresholds), we guide them to generate questions that adhere to specific criteria. This process turns abstract textual logic into a set of actionable, reproducible data points, enabling a systematic approach to content creation.
The integration of LLMs allows us to automate and refine this data-driven generation. By embedding quantifiable metrics into the model’s input, we can produce a series of questions that align with predefined distributions — such as difficulty or topic coverage — while maintaining relevance to current legal contexts. This method not only enhances efficiency but also ensures that the output is consistent and adaptable, mirroring the rigor of scientific experimentation.
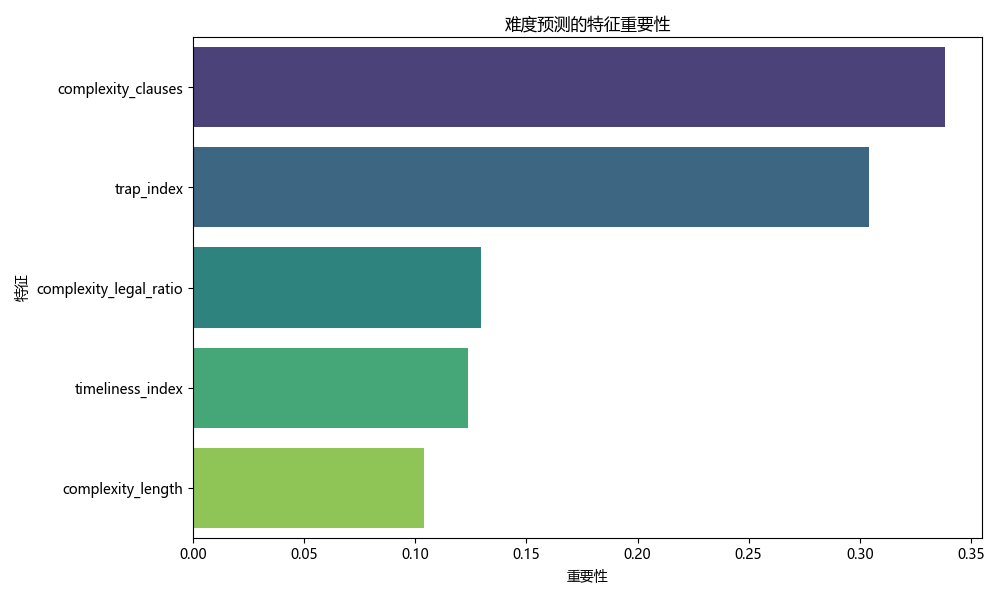

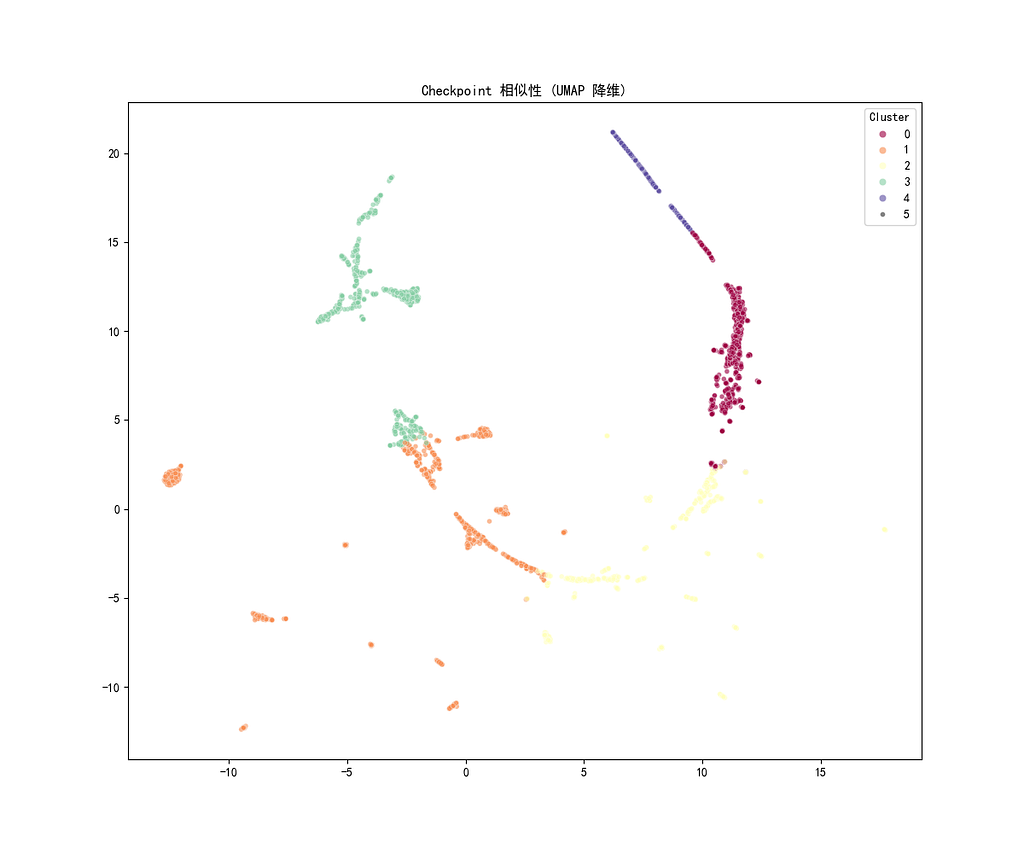
The result is a set of mock questions that balance creativity with precision, offering a practical solution for legal education. This approach opens doors beyond law, suggesting potential applications in fields like history or literature, where narrative content can be quantified — e.g., analyzing event relationships to design structured exercises.
This fusion of LLM technology and quantitative analysis exemplifies how AI can elevate humanities-based education. By converting textual logic into measurable data, we pave the way for innovative, scalable learning tools. The journey from intuition to data-driven design highlights AI’s transformative potential in shaping the future of education.