我是如何用 Git Worktree + Skill 实现多任务并行开发的
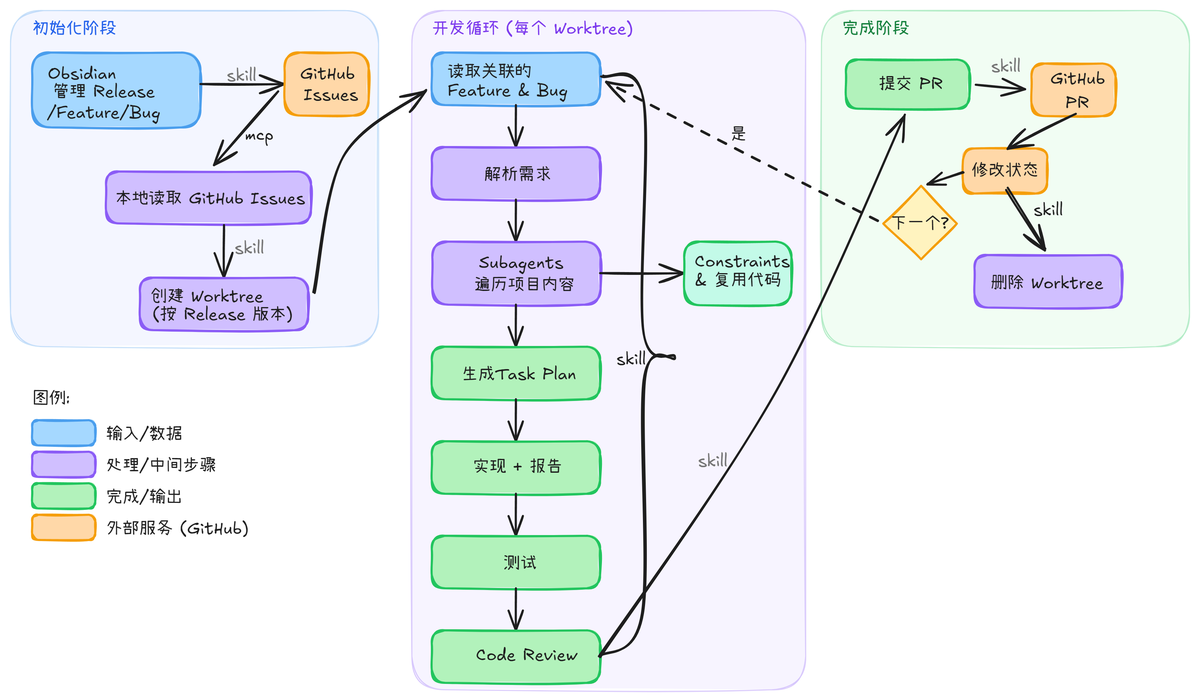
在之前的文章中,我介绍了我是如何在 Obsidian 中管理 release、feature 和 bug,把开发任务结构化。当任务被组织好之后,另一个更重要的事情是这些任务如何被并行高效执行。如果仍然沿用传统的开发方式,即一个分支对应一个功能、线性推进,那么即使有 AI 的帮助,本质上仍然是单线程开发。一旦任务变多,人需要不断在不同上下文之间切换,效率反而会下降。 所以我现在把release 作为更高一层的执行单位,并引入多个 worktree 并行开发的方式。
用 release 切分并行单元
在这套结构中,每一个 release 对应一个独立的 worktree。这个 worktree 内会包含该版本下的所有 feature 和 bug,它不再是一个功能分支,而是一个完整的开发上下文。 这意味着,并行的粒度从一个功能变成了一个业务目标。release 的划分必须是收敛的。否则并行会导致代码变得混乱。
我个人更倾向于按业务目标来划分一个 release,也就是一组共同服务于同一目标的改动。 但这不是唯一方式,也可以按照模块、代码路径,甚至改动类型来组织。关键不在于用什么维度,而在于是否控制住了改动范围。只有当每个 worktree 的边界足够清晰时,并行才是可控的。
即使做了分割,多个 worktree 并行开发仍然不可避免会产生冲突。但是在设计中,我会刻意做几件事来降低 merge 的复杂度:通过清晰的模块划分减少交叉修改,在 release 阶段限制改动范围,以及在执行过程中通过约束(constraints)控制修改边界。
每个 worktree,都是一个自动化开发单元
如果只停留在 worktree 层面,其实只是解决了“可以并行”的问题。在我的体系里,每一个 worktree 本质上都是一个独立的自动化开发单元。
这个单元从 GitHub Issue 出发,读取一个 release 下的所有 feature 和 bug,然后通过一组 skill 串起完整的开发流程:需求分析、代码扫描、实施计划(包括具体的测试)、编码实现、自动化测试、代码审查,最终完成提交并更新状态。把这整个流程封装成一个skill,每次通过这个skill可以读取issue从而触发从worktree建立到整个开发流程的完成,当然还是建议最终测试有个人来进行把控。并且整个流程中可以把一些比较费token的过程用便宜的模型来做,譬如代码扫描,可以用一个便宜的模型开多个subagents来跑(直接把调用方法写到skill里面)。
流程驱动
在执行过程中,每一个阶段都会产出结构化的信息,用于支撑下一步决策。这些信息不会散落在项目中,而是集中在一个临时的文件中,我一般用info文件夹。在整个流程的skill中,会让它不断地去参考这个文件夹里面的内容,并且阶段性地输出分析和总结。 这样做有两个好处: 第一,每一步都有清晰的输入和输出,流程更稳定。
第二,这些中间信息可以被 agent 理解和复用,而不是每一步都从头开始推理。 最终,在整个流程结束之后,再将必要的结果沉淀到正式的文档或代码中,其余中间信息则不会污染项目本身。
最后,如果整个流程中有一些问题,可以先让AI把现有的流程问题解决掉,并且调用Skill Evolution Manager 这个skill。这个skill可以把你和AI之前对话中改进的问题沉淀下来,用于改进这个流程的skill。
从“写代码”到“设计执行结构”
回过头来看,这套方法的变化并不在于使用了哪些工具,而在于开发的重心发生了转移。过去的重点是写代码,而现在更重要的是如何设计流程、定义约束,以及组织执行路径。当这些被结构化之后,agent 才能稳定地参与进来,而不是停留在“辅助写代码”的层面。 这套方式并不是一个必须照搬的标准流程,而是我在实际使用中逐渐总结出来的适合我自己开发流程的一种组织方法。具体的工具、实现细节都可以替换,但背后的核心是一样的:把开发过程拆分为可以被执行、被约束、被组合的单元。 在 AI 逐渐进入开发流程的背景下,这种能力,可能会变得越来越重要。